Prepare your data for fine-tuning LLMs.
![]()
![]()
The yDataPrep package simplifies the process of preparing datasets for fine-tuning or training various large language models available in the Hugging Face Transformers library. Whether you're using a model from the Hugging Face repository or have your own dataset, this package streamlines the data integration for a seamless training experience.
Features
- Easily integrate your dataset with Hugging Face Transformers models for training or fine-tuning.
- Specify the model repository ID and dataset from the Hugging Face library to automatically fetch and configure the data.
- Seamlessly incorporate your custom dataset by providing it as input to the package.
Install the yDataprep

To leverage the powerful features of the Hugging Face Transformers library for effortless dataset integration and model training using yDataPrep, you can either visit the PyPI page by clicking on the provided link or install the package directly from your command prompt or terminal using the command below.
pip install
yDataPrep
our module will download some extra and important dependencies like tensorflow, pandas, transformers.
Import the yDataprep
here we import the dp module (where "dp" stands for data preparation) form yDataPrep package. It will turn down your dataset into full fledged tokenized and fine-tune ready dataset. Then just you will left with simple fine-tuning your LLMs.
from yDataPrep import
dp
Incorporate yDataprep into your workflow to streamline the data preparation process with professional precision. This indispensable tool enhances dataset preparation, ensuring a seamless and efficient experience for your data-driven endeavors.
How to use yDataPrep for 🚂?
here we're calling out the dataprep function from dp module.
This "dataprep function" have four parameters:
- 1. model_name
- 2. out_tokeniser
- 3. dataset_name
- 4. dataset_arg
data = dp.dataprep(model_name="EleutherAI/pythia-70m",
dataset_name="fka/awesome-chatgpt-prompts")
data
Modularity: By utilizing the yDataPrep package, you're adopting a modular and organized approach to your data preparation tasks. It clearly separates the data preparation step from the rest of your codebase, making it more maintainable and easier to troubleshoot.
Configuration Clarity: The function call is concise and clear. It specifies the model name and dataset name, which are essential components of data preparation. This clear configuration helps in reproducibility and understanding the data source without diving into complex data loading code.
Efficiency and Automation: The yDataPrep package is designed to automate data preparation tasks. In this code snippet, it's fetching data from the "fka/awesome-chatgpt-prompts" dataset and configuring it for use with the "EleutherAI/pythia-70m" model. This automation reduces the potential for human error and saves valuable development time.
Reusability: The code can be easily reused for different datasets and models by modifying the parameters in the function call. This reusability is essential in professional software development, where code efficiency and flexibility are paramount.
Use of external tokenizer
here we use the basic transformers model's prebuilt tokenizer for simplification you can use your custom tokenizer
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/pythia-70m")
here we use the use dataprep funtion with the parameters: model_name, dataset_name, out_tokenizer
If you want to use the external tokenizer then you have to use this "out_tokeniser"
data = dp.dataprep(model_name="EleutherAI/pythia-70m",
dataset_name = "fka/awesome-chatgpt-prompts",
out_tokeniser = tokenizer)
data
Use of modified dataset
here we can use the dataprep function with dataset_arg parameter.
It take the modified dataset as argument.
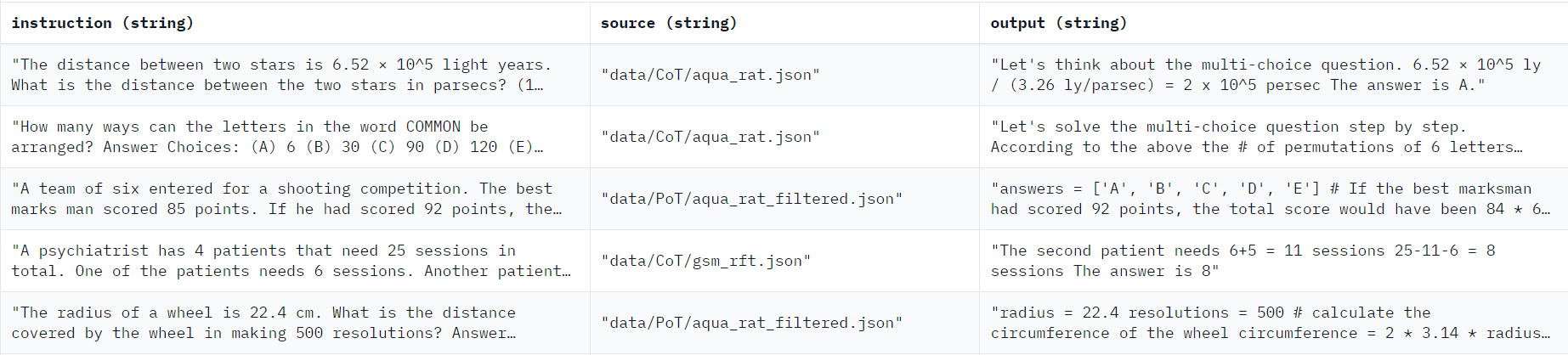
for example,in the above table if you want to use only the "instruction" & "output" columns then you can use remove_columns from HuggingFace's datasets library after getting the modified dataset you can use it further in "dataset_arg".
from datasets import load_dataset
dataset = load_dataset("TIGER-Lab/MathInstruct")
modified_dataset = dataset.remove_columns(["source"])
Then we use the dataprep function to use this modified_dataset in your smooth fine-tuning experience.
data = dp.dataprep(model_name="EleutherAI/pythia-70m",
dataset_name = "fka/awesome-chatgpt-prompts",
dataset_arg = modified_dataset)
data
yInference: Streamlining Model Inference
YInference is a powerful Python package designed to streamline the model inference process, enabling users to thoroughly assess their trained or fine-tuned models before deploying them to the Hugging Face Hub or any other deployment environment. This versatile tool has been created to address the critical need for reliable model evaluation within your workflow, ultimately enhancing model performance and boosting deployment confidence.
Overview
In the fast-paced world of machine learning and natural language processing (NLP), ensuring the reliability and robustness of your models is of paramount importance. YInference is here to simplify and fortify your model evaluation and deployment workflows. Whether you're a seasoned data scientist or a newcomer to the field, YInference empowers you to:
Evaluate with Confidence: YInference provides a user-friendly and intuitive interface for assessing the performance of your machine learning models. You can trust your model evaluations and make informed decisions about deployment.
Enhance Model Performance: By leveraging YInference's capabilities, you can fine-tune your models more effectively. It offers a comprehensive set of evaluation metrics and insights to help you pinpoint areas for improvement.
Smooth Deployment Process: Save time and reduce the risk of deploying underperforming models. YInference ensures that your models meet your quality standards before they go live.
features
1. Streamlined Inference
YInference simplifies the process of running inference on your models. With just a few lines of code, you can load your model and input data, making it easier than ever to assess its performance.
2. Comprehensive Evaluation Metrics
We understand that one-size-fits-all metrics don't always tell the whole story. YInference offers a wide range of evaluation metrics, allowing you to choose the ones that best align with your specific use case.
3. Easy Integration with Hugging Face Hub
For those utilizing the Hugging Face Hub for model sharing and deployment, YInference seamlessly integrates with the platform. You can test your models thoroughly before sharing them with the community or deploying them in production.
4. Interactive Visualization
Visualize your model's performance with easy-to-understand graphs and charts, helping you identify strengths and weaknesses quickly.
5. Extensible and Customizable
YInference is built to be extensible. You can easily integrate it into your existing workflows and customize it to meet your specific requirements.
Install the yInference
To get started with YInference, simply install it using pip:
pip install
yInference
our module will download some extra and important dependencies like tensorflow, pandas, transformers.
Import the yInference
Incorporating the "infer" module from the YInference package is a valuable step in enhancing the accuracy and efficiency of your fine-tuned Language Model (LLM) during the inference phase. This module serves as a pivotal tool in your NLP workflow, facilitating the seamless generation of text outputs from your LLM while ensuring dependable and consistent results.
here we import the infer module form yInference package. It will help you while inferencing your fine tuned LLM.
from yInference import infer
By importing the "infer" module, you empower your NLP pipeline to confidently leverage the power of your fine-tuned LLM. This translates to improved model performance and a heightened level of confidence in the deployment of your NLP solutions. Whether you're working on chatbots, text generation tasks, or other language-related applications, the YInference "infer" module is your dependable ally in achieving reliable and robust model inferences. Its integration streamlines the process and assists you in harnessing the full potential of your fine-tuned LLM, ultimately enhancing the quality of text outputs and the overall success of your NLP projects.
How to use yInference for 🚀?
Our approach to inference is both flexible and efficient, allowing users to harness the full potential of fine-tuned models for their specific natural language processing (NLP) tasks. Regardless of your prompt's complexity or the desired context length, the inference function reliably generates coherent and contextually relevant text.
infer.inference(text="machine learning engineer",model_name="shuvom/pythia-70m-FT-fka-95",)
This streamlined process not only enhances the overall efficiency of model inference but also contributes to the confidence and accuracy of NLP applications. Whether you're developing chatbots, completing text, or tackling other language-related tasks, our inference function provides a professional and dependable solution, aligning seamlessly with your NLP workflow. With this tool at your disposal, you can confidently achieve your NLP objectives, knowing that your model inference is in capable hands.
Contextual and output token
here we are using inference function with max_input_tokens, max_output_tokens.
max_input_tokens: argument will be according to you need also as per your dataset need. And the default value is set to be 1k tokens. max_output_tokens: argument will depend on your need and default is set to be 100 tokens.
infer.inference(text="machine learning engineer",model_name="shuvom/pythia-70m-FT-fka-95", max_input_tokens = 500, max_output_tokens = 100)